
Hadoop 3.2の環境構築
だいぶ今更感のあるHadoopですが、ggってみると案外Hadoopの記事が入門とか環境構築して試してみたよ系の記事しかなかった。
しかもバージョンが2.xのものばかり…
情報がどれも中途半端に古い。
オマケに今台湾にいてで書籍も入手が難しい。
ということで今回はHadoop3.2(安定版)をUbuntuにインストールして使ってみようという記事を書くことにしました。
この記事では環境構築だけ行って、次の記事で転置インデックスを動かすことにします。
ユーザー追加
hadoop用のユーザーを作ります。
$ sudo adduser hadoop
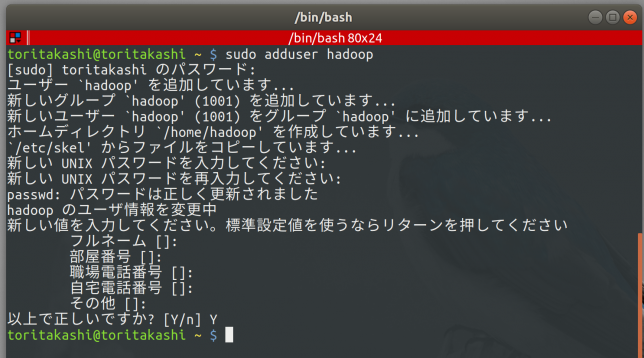
ユーザーを作成しました。
sshのところまではhadoopユーザでなくても問題ないです。
次はhadoopの動作に必要なものをぶち込んでいきます。
動作に必要なもの
rsync
ubuntuならばrsyncは既にインストールされていると思いますので割愛。
SSH
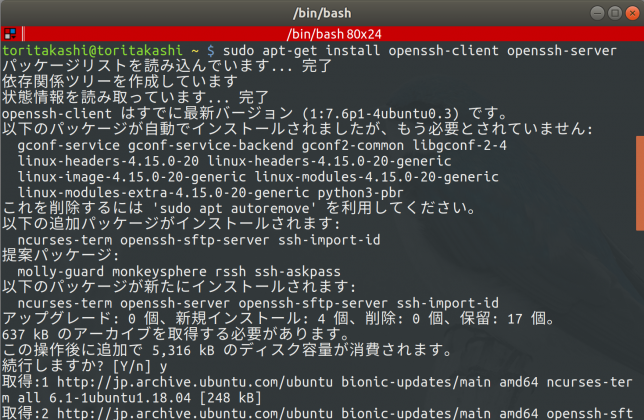
openssh-clientはインストール済みだと思いますが、openssh-serverはデフォルトでは入っていないのでインストール
$ sudo apt-get install openssh-client openssh-server
JDK
Hadoopはjavaで書かれているのでjavaが動くようにしてやる必要があります。
今回はOracleのJava 8をインストールします。
ここでJava11をダウンロードしてはいけません。
Hadoop 3.xはJava11に対応していません。
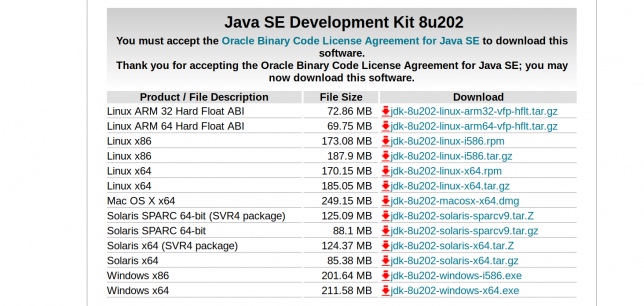
まずは下のOracleのサイトにアクセスして、JDKをダウンロードしてください。
今回の環境はx64のubuntuなのでjdk-8u202-linux-x64.tar.gzをダウンロードしています。
各自の環境に応じて適宜読み替えてください。
ダウンロードができたら/optに展開します。
所有者はユーザーにしておきます。
$ sudo mv ./jdk-8u202-linux-x64.tar.gz /opt $ sudo tar -zxvf /opt/jdk-8u202-linux-x64.tar.gz $ sudo chown -R YourUserName jdk1.8.0_202
ミスった痕跡が笑
/usr/binにシンボリックリンクを貼ってterminalから直接java, javacを叩けるようにします。
$sudo update-alternatives --install /usr/bin/java java /opt/jdk1.8.0_202/bin/java 100 $sudo update-alternatives --install /usr/bin/javac java /opt/jdk1.8.0_202/bin/javac 100
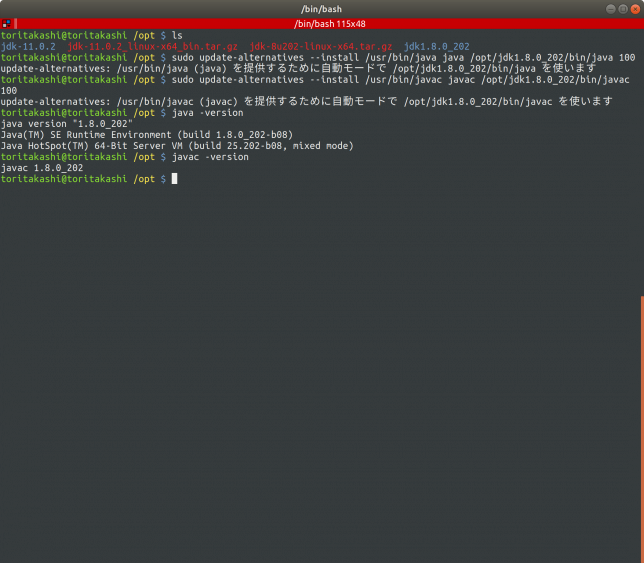
java単体で動作しているので無事に設定が完了しました!
SSHの設定
hadoopはsshを経由して関連コンポーネントを立ち上げるので、sshの設定をしてあげる必要があります。
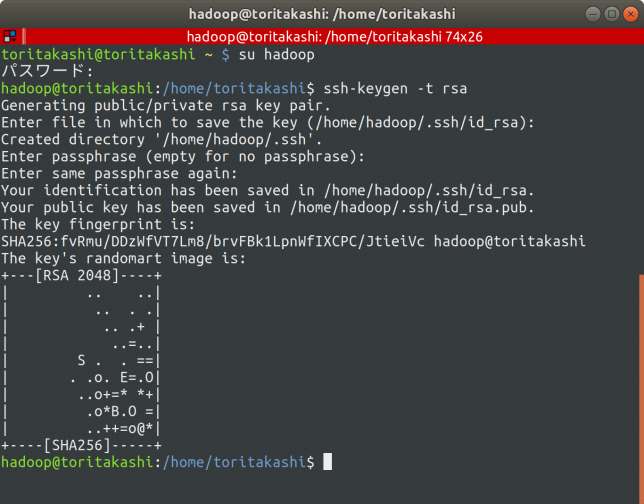
先程追加したhadoopユーザーにログインしてsshの設定を行います。
この段階ですが、Enter passphraseでパスワードを設定しないでください。
Hadoopは鍵なしSSHを用いてサービスを立ち上げます。
パスワードありの場合の設定項目を探しましたが見当たりませんでした。
$ su hadoop $ ssh-keygen -t rsa
authorized_keysに鍵を追加してsshで接続できるか確認します。
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys $ ssh localhost
はい、無事ログインできました。
Hadoopのインストール
apacheのファイルサーバからHadoopをダウンロードします。
今回はstableディレクトリにあったhadoop-3.2.0をインストールします。
ファイルは以下のページ内のhttp://apache.stu.edu.tw/hadoop/common/から探すことができます。

今回は
apache.stu.edu.tw/hadoop/common/stable/hadoop-3.2.0.tar.gz
をダウンロード&解凍していきます。
$ wget apache.stu.edu.tw/hadoop/common/stable/hadoop-3.2.0.tar.gz $ tar -zxvf hadoop-3.2.0.tar.gz
さあこれでソフトウェア側の準備は整いました!
続いてhadoopの設定です!
環境設定
これから6つのファイルを編集します。
地味につらいですが淡々とやっていきましょう。
.bashrc
まず~/.bashrcに設定を行い起動時に読み込むようにします。
$vim ~/.bashrc
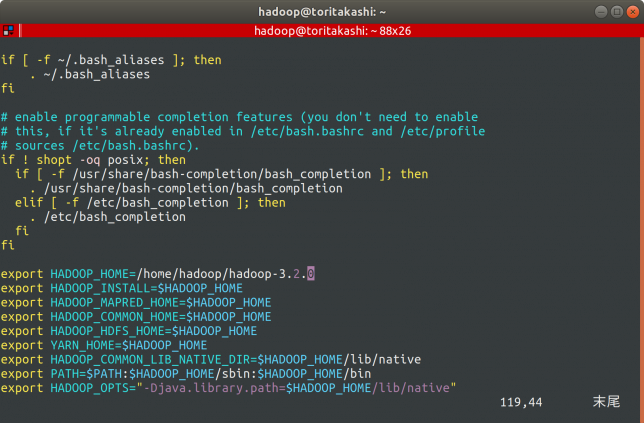
以下の項目をbashrcに追記します。
export HADOOP_HOME=/home/hadoop/hadoop-3.2.0 export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
起動時に毎回読み込むように
$ source ~/.bashrc
をしてあげます。
これでbashrcの設定は完了です!
続いてhadoopの設定を行います。
hadoop-env.sh
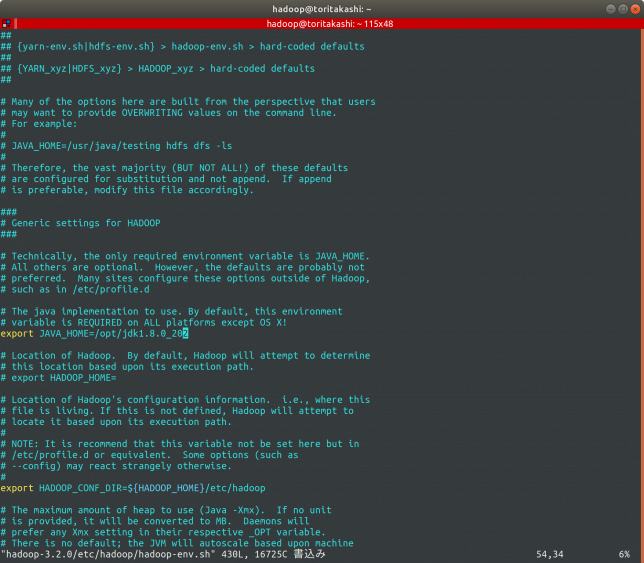
$ vim ~/hadoop-3.2.0/etc/hadoop/hadoop-env.sh
でhadoop-env.shを開き、54行目は
export JAVA_HOME=/opt/jdk1.8.0_202
68行目はコメントアウトを外して
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoopにします。
core-site.xml
$vim ~/hadoop-3.2.0/etc/hadoop/core-site.xml
で編集できます。
最初の状態はこんな感じ。
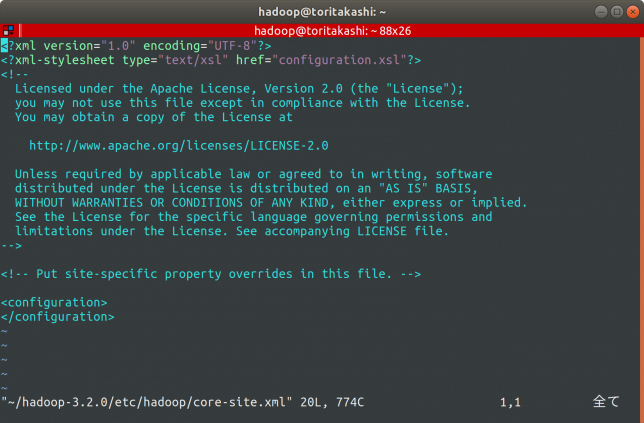
この<configuretion>と</configuration>の間に以下の設定を記述します。
<property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/hadoop/hadooptemp</value> </property>
するとこんな感じになります。
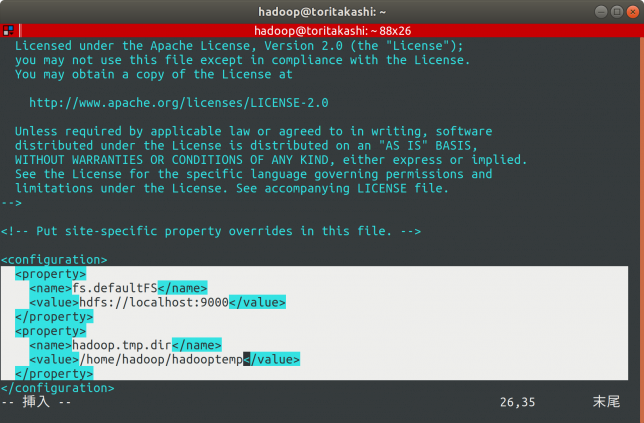
忘れずに
$ mkdir ~/hadooptemp
をしてディレクトリを作成しましょう。
hdfs-site.xml
$ mkdir -p hdfs/namenode $ mkdir -p hdfs/datanode
で予めディレクトリを作成しておき、
$ vim ~/hadoop-3.2.0/etc/hadoop/hdfs-site.xml
で編集を行います。
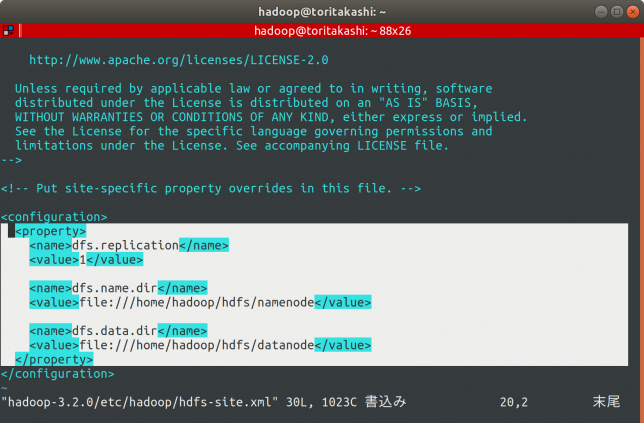
最初はこんな感じなので、同様に<configuration></configuration>内に以下の内容を記述します。
<property> <name>dfs.replication</name> <value>1</value> <name>dfs.name.dir</name> <value>file:///home/hadoop/hdfs/namenode</value> <name>dfs.data.dir</name> <value>file:///home/hadoop/hdfs/datanode</value> </property>
こんな感じになります。
replicationはこのPC単体で試すだけなので1です。
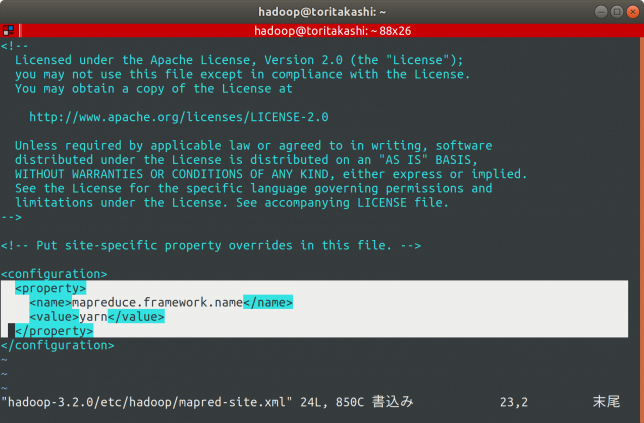
mapred-site.xml
$ vim ~/hadoop-3.2.0/etc/hadoop/mapred-site.xml
を編集します。
ファイルを開くとやっぱり以下のような感じになっていると思うので、これに以下の内容を同様に追記します。
これはyarnを使うよ〜という設定です。
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
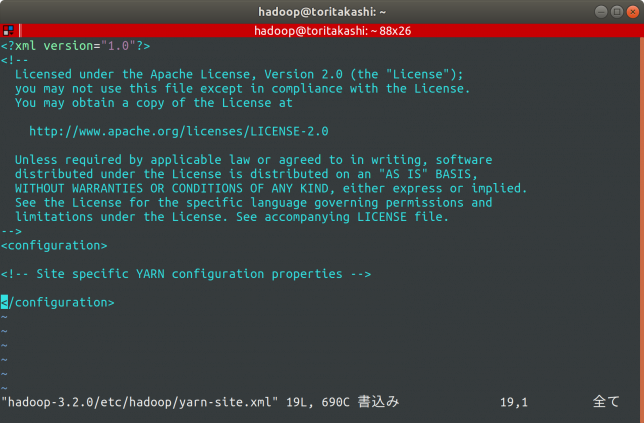
yarn-site.xml
$ vim
こちらも同様に設定します。
ファイルを開くと以下のようになっているので、同様に追記していきます。
<property> <name>mapreduceyarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property>
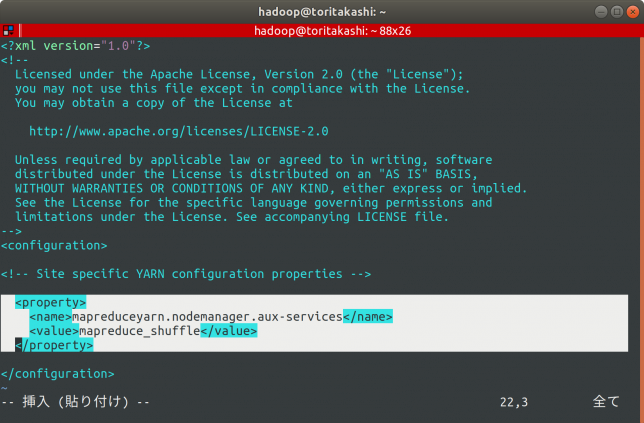
これでファイルの設定は完了しました!
環境設定が終わったので、続いて初期設定です(環境設定は初期設定ではなかった…?)
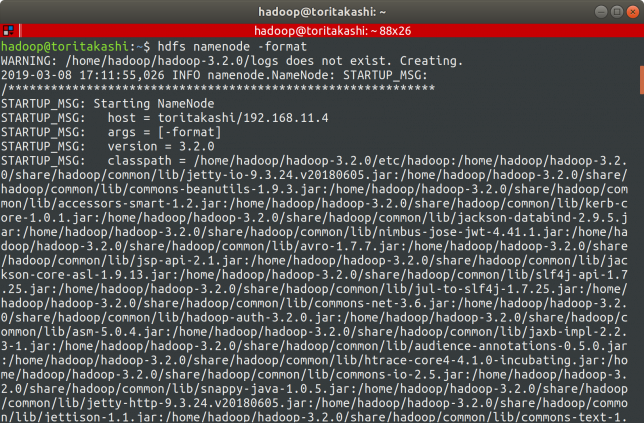
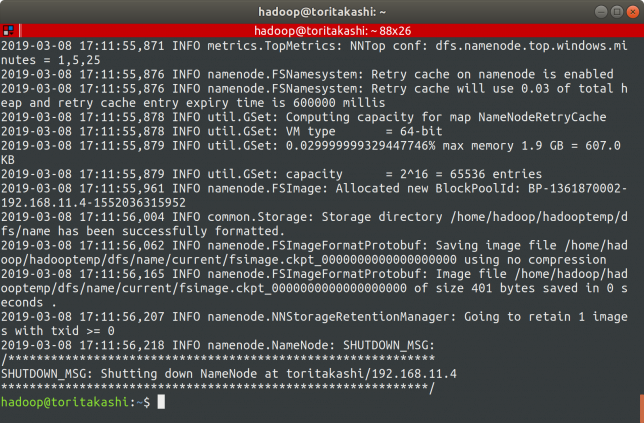
HDFSでディレクトリをフォーマットする
$ hdfs namenode -format
でフォーマットを行います。
サービス起動
dfsとyarnを立ち上げて、jpsで動作しているか確認します。
$ start-dfs.sh $ start-yarn.sh $ /opt/jdk1.8.0_202/bin/jps
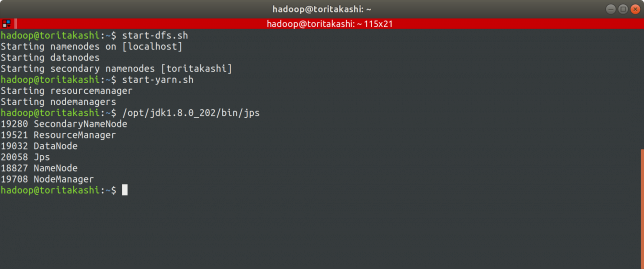
はい!
- SecondaryNameNode
- ResourceManager
- DataNode
- NameNode
- NodeManager
が起動しているのが確認できましたね!
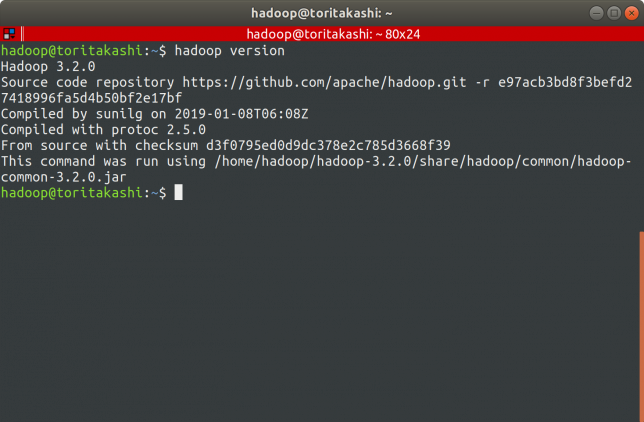
バージョン確認
$ hadoop version
または
$ hdfs version
でhadoopのバージョンを確認することができます。
NameNodeのWebUIにアクセス
hdfsフォーマットで管理されているファイルはNameNodeのWebUIを通じて参照することができます。
まずは試しにディレクトリを作ります。
$ hdfs dfs -mkdir -p testdir1 $ hdfs dfs -mkdir -p testdir1/testdir2 $ hdfs dfs -mkdir -p testdir3 $hdfs dfs -ls
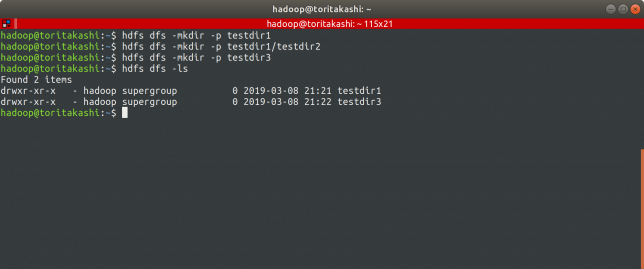
ここでNameNodeのWebUIにアクセスします。
localhost:9870でアクセスが可能です。
開くとこんなページが出てきます。
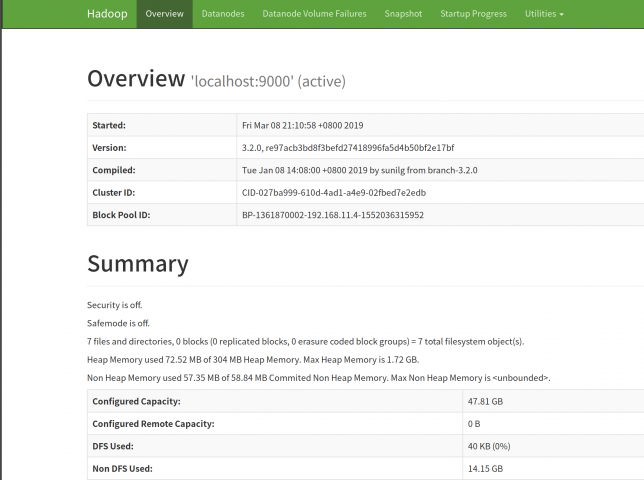
Utilities > Browse the file systemを開きます。
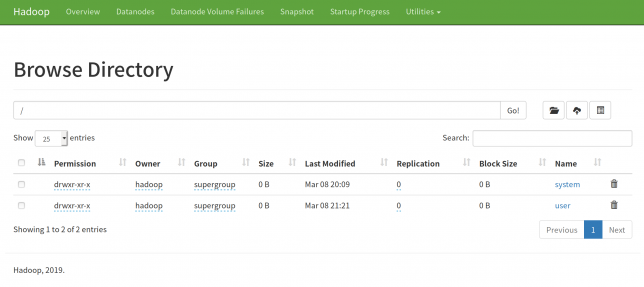
User/hadoop/に作ったディレクトリがあることが確認できます。
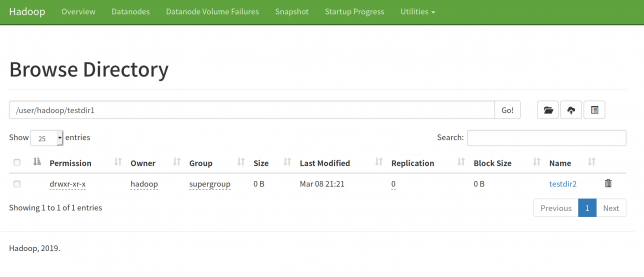
下の写真はtestdir1の中です。
ブラウザ経由でファイルをアップロード,ダウンロードしたりディレクトリを作成することが可能です。
まさにファイルブラウザという感じですね。
YarnのWebUIにアクセスする
YarnのWebUIには
localhost:8088でアクセスすることができます。
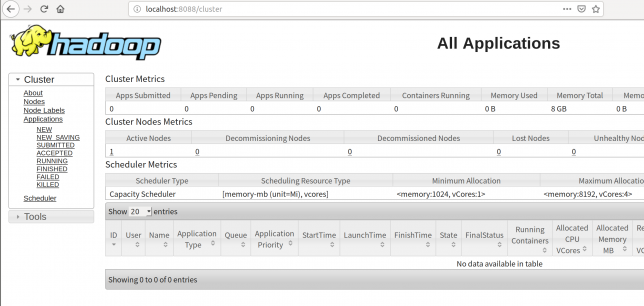
Java11だとこいつが立ち上がってくれません笑
まぁなにはともあれセットアップは無事終了です、お疲れ様でした!
この次はMapReduceでinverted index(転置インデックス)のアルゴリズムを実装する話です。
ハマったポイント
最初にJava 11を入れてやっていたが(ところどころで辛酸を舐めたjava11の文字が見えているはず…)
最後のResourceManagerが立ち上がらなかった。
調査していると

こちらのページに行き着いた。
どうやらHadoop 3.xはJava8までしか対応していないそうだ。
参考
https://linuxconfig.org/how-to-install-hadoop-on-ubuntu-18-04-bionic-beaver-linux
https://stackoverflow.com/questions/19641326/http-localhost50070-does-not-work-hadoop
http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html








コメント