
Hadoop
最初は用語の説明からいきましょう。
Hadoopはビッグデータをより安価,より効率的に分散並列処理する必要があったgoogleが発表した論文をもとにしたシステムです。
HDFSファイルシステムとmapreduceという処理機構を基礎としています。
hadoopは分散並列処理とプログラムのロジックを切り離すため、分散並列処理そのものはすべてhadoopが担います。
Hadoop streaming
HadoopはJavaで書かれていることから、最初はmapper, reducerもjavaで書く必要がありました。
またC++のライブラリもあることにはありますが、情報が少なく扱いにくいものでした(体験談:リンカー周りで死んだ)。
しかしこのHadoop streamingを使うことで、標準入出力を扱えるプログラミング言語であればhadoopを利用できるようになったのです。
Hadoop streaming自体はjar形式のファイルで、hadoop jarコマンドで実行しinput,mapper,reducer,outputなどの設定はコマンドライン引数を用いて行います。
転置インデックス
転置インデックスは、要は索引を作るアルゴリズムです。
これは検索システムの主流となっているアルゴリズムです。
索引検索は、grepのようなファイルの数に比例して処理速度の落ちる順次検索と異なり、高速に単語を検索することができます。
ただし予め検索のための索引を作っておく必要があります。
そのテーブルを作るアルゴリズムがこの転置インデックスというわけです。
今回は検索までは扱いません。
またキーは通常文書IDを用いますが、わかりやすくするためにここでは文書名を用いています。
挙動
イメージ的には、文章中に出てきた単語(キー)をドキュメント名(値)と紐付け、キーと値を逆転させる感じです。
例えば
$ cat aaa.txt りんご みかん りんご $ cat bbb.txt りんご ぶどう りんご
という2つのテキストファイルの索引を作ってみましょう。
まず文章中に出てきた単語(キー)をドキュメント名(値)と紐付けでみましょう。
すると以下のような感じになるはずです。
$ cat intermediate_kvs.txt aaa.txt りんご aaa.txt みかん aaa.txt りんご bbb.txt りんご bbb.txt ぶどう bbb.txt りんご
そしてキーと値を逆転させましょう。
$cat inverted_intermediate_kvs.txt りんご aaa.txt みかん aaa.txt りんご aaa.txt りんご bbb.txt ぶどう bbb.txt りんご bbb.txt
ただこのままだと重複したキーが複数ありますし、またKey-Valueデータなので可用性が低いですね。
ということでこれを集計します。
$cat output.txt りんご aaa.txt bbb.txt みかん aaa.txt ぶどう bbb.txt
これで索引ができました。
使い方は本の索引を思い出してもらえばわかりやすいですね。
例えば「みかん」がどこに書かれているのかを知りたかったら、索引を参照して「みかん」が書かれているファイルを探すことができます。
Hadoop streamingで転置インデックス
前置きが長くなりましたが、Hadoop streamingを使って転置インデックスのアルゴリズムを動かします。
この記事で使っているコードなどはすべてGitHubにおいてあります。

早速やってみましょう。
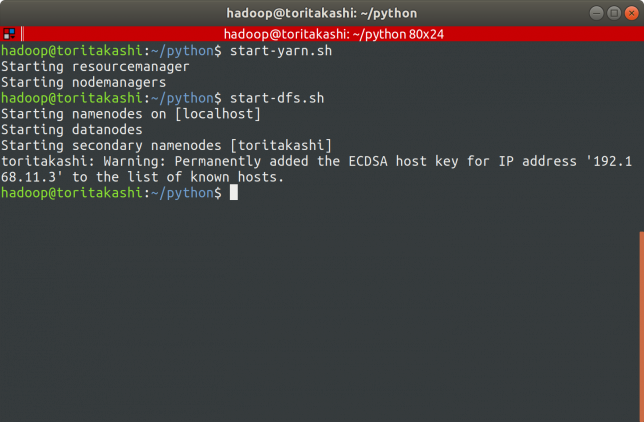
Hadoopを起動
$ ./start-yarn.sh $ ./start-dfs.sh
Hadoop streamingをダウンロード
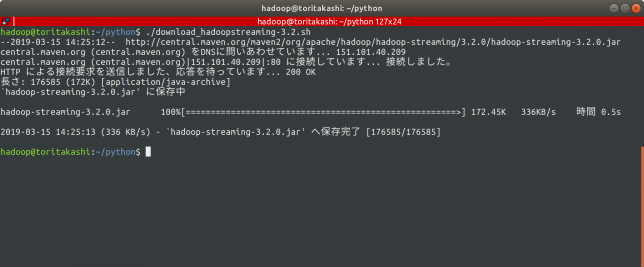
MavenリポジトリにHadoop streamingのファイルが公開されています。

自分の環境のバージョンはHadoop v3.2なのでそれに対応したHadoop streamingをダウンロードします。
$ ./download_hadoopstreaming-3.2.sh $ cat ./download_hadoopstreaming-3.2.sh #!/bin/bash wget http://central.maven.org/maven2/org/apache/hadoop/hadoop-streaming/3.2.0/hadoop-streaming-3.2.0.jar
MapperとReducerを実装する
inverted_index_mapper.py
inverted_index_reducer.py
起動
invindex.sh
先にファイルの構成を確認しておきます。
$ ls
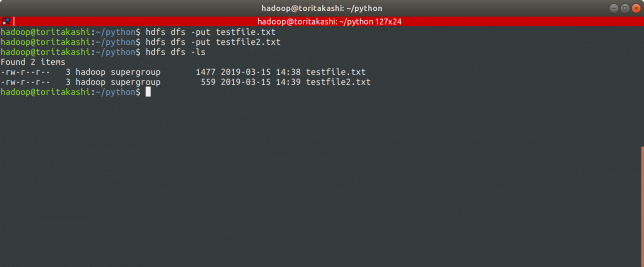
入力ファイルをアップロード
$ hdfs dfs -put testfile.txt $ hdfs dfs -put testfile.txt
実行
$ ./invindex
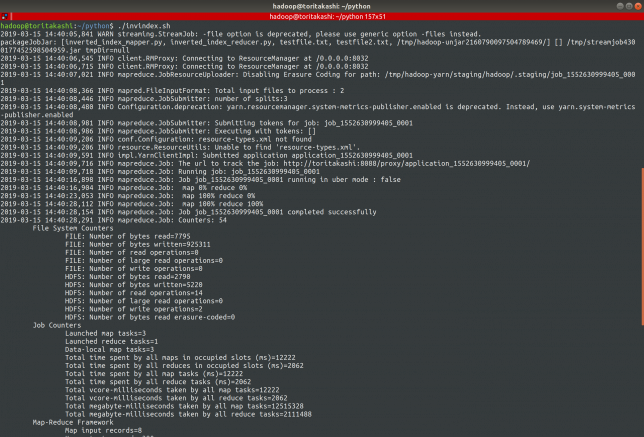
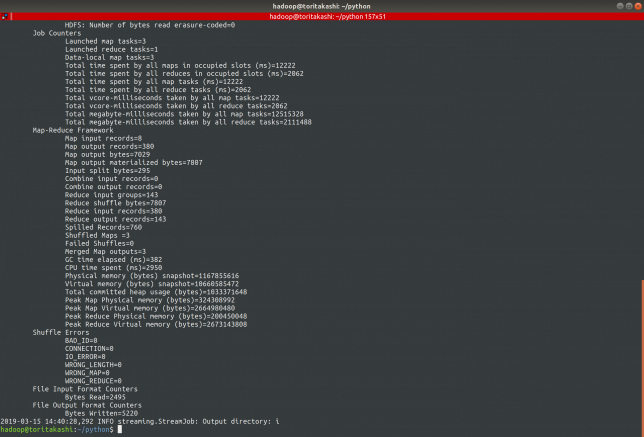
結果を見る
localhost:8088にアクセスして、ジョブが成功したかを確認したりログを見たりできます。
右下にSUCCESSと出ているのが見えますね!
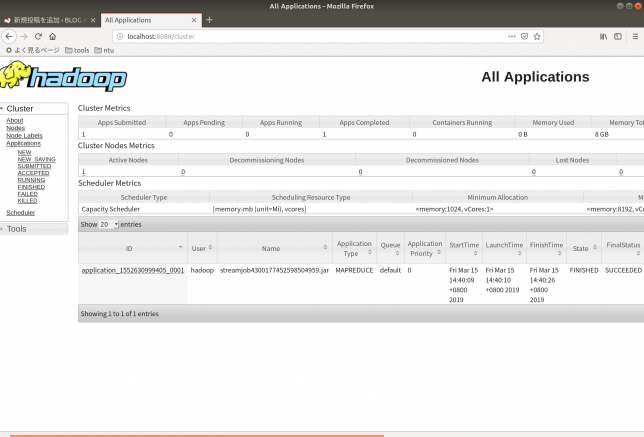
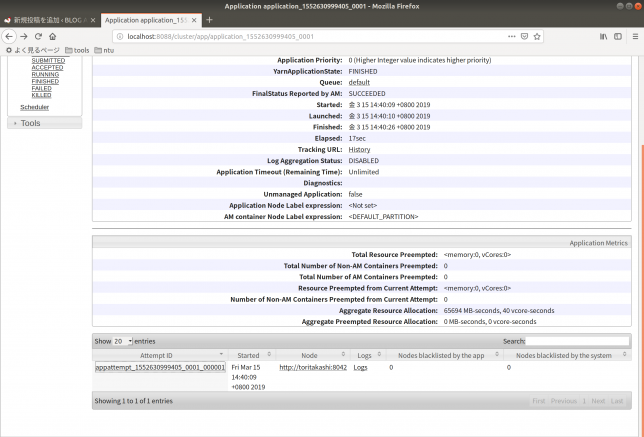
application_XXXXXのようになっているリンクをクリックすると詳細ページに飛びます。
下の方に行くとLogを見ることができるリンクがあります。
ほぼ全てterminalに出ている情報なので、作業で詰まった時あんま役に立ちませんでした(個人の感想です)
実行結果はスクリプトに設定されているiディレクトリの中、i/part-00000に格納されています。
長くなるので結果は省略します。
気になる人はGithubのpart-00000を参照してください。
$ hdfs dfs -get i/part-00000
このファイルはWebUIを通じてダウンロードすることもできます。
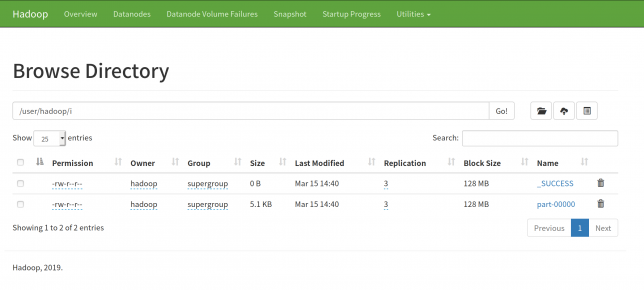
localhost:9870にアクセスして、ファイルブラウザを開きます。
/user/<username>/iに結果が入っているはずです。
Tips
hadoop streamingで使うpythonスクリプトのデバッグ
$ cat testfile.txt | python3 inverted_index_mapper.py | sort | python3 inverted_index_reducer.py
引数は適当に調整してください。
実際のところHadoop streamingのデバッグは非常にやりにくいです。
os.environ["map_input_file"]はHadoop環境上でのみ定義さてれているので、ローカル環境でのデバッグはできません。
os.environ["map_input_file"]を使う場合は、その部分をアドホックなコードで置き換えてデバッグしてみてください。
またHadoop streamingは標準入出力を使った処理を行っているので、デバッグ時に入れた標準出力を行う命令はすべてコメントアウトしてください。
参考文献
http://gihyo.jp/dev/serial/01/search-engine/0003








コメント